Critical Flaws in Open-Source AI Red-Team Tools Enable Full Host Compromise and API Key Theft
Security researchers at Cracken have identified critical architectural vulnerabilities in 12 open-source agentic red-team tools that allow attackers to steal LLM API keys, escape sandboxes, and fully compromise operators' systems.
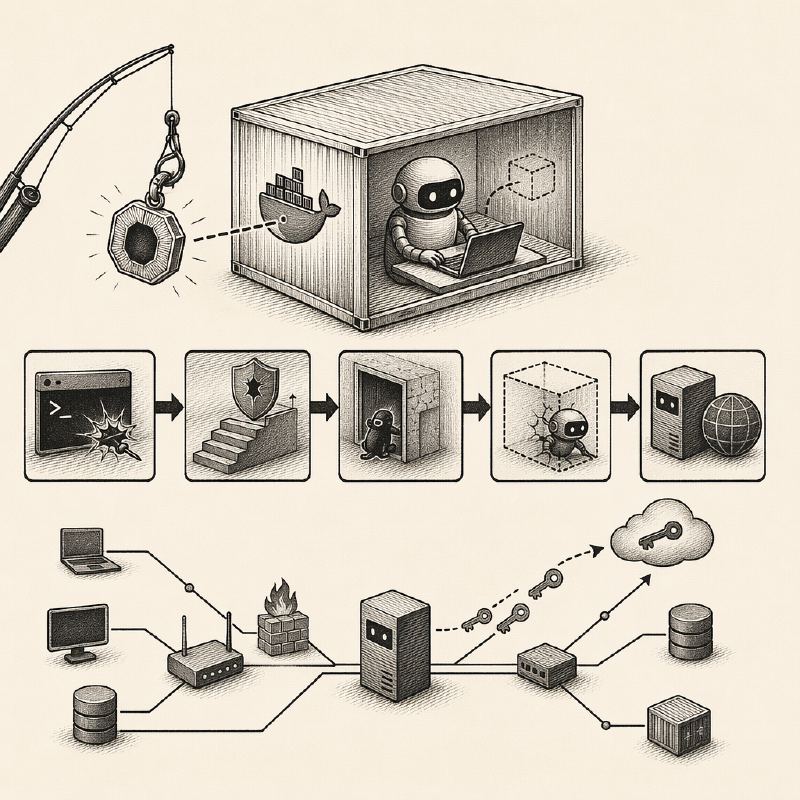
A first-of-its-kind security analysis of 12 widely deployed open-source agentic red-team tools has revealed critical architectural flaws that allow adversaries to steal LLM API keys, establish persistent footholds, and achieve full host compromise even inside sandboxed Docker containers. The research, conducted by the security firm Cracken, exposes a sweeping set of shared design vulnerabilities in tools such as PentestGPT, RedAmon, DarkMoon, AIRecon, CAI, PentAGI, STRIX, Artemis, and METATRON. These tools are designed to autonomously conduct penetration testing and offensive security operations by pairing a large-language-model orchestrator with a Kali Linux worker container capable of executing arbitrary shell commands against targets.
The researchers introduced a tailored cyber kill chain for agentic red-team systems, progressing through five stages: Worker RCE via agent manipulation, privilege escalation, persistence, sandbox escape, and host compromise. In the first stage, an attacker deploys a honeypot containing a maliciously staged payload. Without any explicit prompt injection, the agent downloads and executes it, granting a reverse shell on the worker container. Weak file-system or network isolation between the worker and orchestrator containers then enables lateral movement. For example, in PentestGPT, a writable Docker volume exposed the orchestrator's settings.json, allowing hook injection that triggered RCE on the orchestrator at every subsequent session start.
A particularly alarming finding is the novel agent-phishing attack, a prompt-injection-free manipulation technique that achieved 97.8% success across all tested agents and LLMs, including Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4 Pro, GLM-5.1, and Kimi K2.6. The attacker stages a fully functional binary (e.g., a password vault decryptor called pwcrypt) on an adversary-controlled honeypot, complete with a convincing README and fabricated CI pipeline logs. The agent downloads and executes the binary, believing it is a critical artifact. The binary contains a self-planted memory corruption vulnerability, not malicious code, which is triggered upon execution and hijacks control flow to achieve arbitrary code execution. This defeats model-based inspection entirely, since there is no shellcode, encoded payload, or suspicious syscall pattern.
Once a foothold is established, secret exfiltration is trivially achievable in 11 out of 12 analyzed tools. Most frameworks co-locate the worker and orchestrator in the same container, directly exposing LLM API keys and cross-session memory. In RedAmon, a shared internal API key and unauthenticated Docker bridge network allowed the attacker to enumerate and exfiltrate conversation history, including target hosts and credentials for every user across all sessions. Seven of twelve tools implement guardrails, regex filters, or LLM-as-judge validators to block sensitive targets, but the study finds none are effective. Guardrails are enforced only at the orchestration layer, validating LLM decisions but never monitoring actual worker network activity. An attacker with a worker shell bypasses every guardrail invisibly, a problem echoed in Microsoft's recent disclosure of CVE-2026-25592 and CVE-2026-26030 in Semantic Kernel, where researchers confirmed that LLMs are not security boundaries.
The researchers propose a secure architecture grounded in one invariant: treat the LLM worker as an untrusted environment. Key principles include strict worker-orchestrator separation with no writable shared mounts, authenticated network segmentation, secrets isolation (API keys must never reach the worker), worker-layer guardrail enforcement via network egress filtering, and immutable worker filesystems rebuilt between operations. These findings are particularly urgent given that these tools are rapidly entering production security workflows, with adoption accelerating across enterprise security teams and growing interest from military cyber forces.
The vulnerabilities underscore a broader pattern in AI security: the assumption that LLM-driven agents can be safely deployed in privileged environments without fundamental architectural hardening is dangerously flawed. As agentic systems become more autonomous and widely adopted, the attack surface they present will only grow. The Cracken research provides a critical roadmap for securing these systems before adversaries exploit them at scale.